How to Determine Which K Means Is Best
Assign each data element to its nearest centroid in this way k clusters are formed one for each centroid where each cluster consists of all the data elements assigned to that centroid. As the value of K increases there will be fewer elements in the cluster.

Account Suspended Life Hacks For School Computer Shortcut Keys Useful Life Hacks
To determine the optimal number of clusters we have to select the value of k at the elbow ie the point after which the distortioninertia start decreasing in a linear fashion.
. Thus for the given data we conclude that the optimal number of clusters for the data is 3. K-Means is based on the concept of distances between your points. In my work I used to follow the result obtained form the elbow method and got succeed with my results I had done all the analysis in the R-Language.
Probably there are lots of posts out there about how K-means clustering works or how it can be implemented with Python. Visualize the K-Means. K 3.
Below I plotted Silhouette plots for K 6 7 8 9 and you can see that we got the highest score for K 7 as we got using the Elbow method. Visualize the K-Means. Choose the number of clusters k.
Second obviously not every attribute should affect the clusters equally. We can find the optimal value of K by generating plots for different values of K and selecting the one with the best score depending on the clusters assignment. K 1.
Note that using B 500 gives quite precise results so that the gap plot is basically unchanged after an another run. There is a popular method known as elbow method which is used to determine the optimal value of K to perform the K-Means Clustering Algorithm. Make an initial selection of k centroids.
Lets visualize our data into two dimensions. If k1 it will be that point itself and hence it will always give 100 score on the training data. WSS measures the compactness of the.
Fviz_clusterkmeansscaled_data centers 2 geom point data scaled_date. Since we determined that the number of clusters should be 2 then we can run the k-means algorithm with k2. So average distortion will decrease.
Choose a value for K. For more such content sub. This video describes the Elbow and Silhouette techniques for finding the optimal K.
K 2. Is there a shortcut by which we can identify the optimum value of clusters in K-means clustering automatically. Quality of a k-means partition.
K-means clustering is an unsupervised iterative and prototype-based clustering method where all data points are partition into k number of clusters each of which is represented by its centroids prototype. The centroid of a cluster is often a mean of all data points in that cluster. Since we determined that the number of clusters should be 2 then we can run the k-means algorithm with k2.
The sharp point of bend or a point of the plot looks like an arm then that point is considered as the best value of K. For this reason we will merely be focusing on choosing the best K value in. The CH-index is another metric which can be used to find the best value of k using with-cluster-sum-of-squares WSS and between-cluster-sum-of-squares BSS.
First we must decide how many clusters wed like to identify in the data. There is no point in hoping that K-Means will figure it out on its own if that can be fixed upstream. GapkGapk 1s k 1.
The clustered data points for different value of k-1. K-means clustering in Python with example. We can look at the above graph and say that we need 5 centroids to do K-means clustering.
Plots a curve between calculated WCSS values and the number of clusters K. How to find Optimal K with K-means Clustering. The basic idea behind this method is that it plots the various values of cost with changing k.
K-means is one of the most widely used unsupervised clustering methods. We all know how K-Means Clustering works. Based on the distance matrix the algorithm will find different clusters.
Fviz_clusterkmeansscaled_data centers 2 geom point data scaled_date. The two approaches above require your manual decision for the number of clusters. The best thing to do and most of the people follow this is to treat k as a hyperparameter and find its value during the tuning phase as just by looking at the graph one cannot determine what k value will be the best.
It scales well to large number of. In the Silhouette algorithm we assume that the data has already been. There are various methods for deciding the optimal value for k in k-means algorithm Thumb-Rule elbow method silhouette method etc.
One of the fundamental steps of an unsupervised learning algorithm is to determine the number of clusters into which the data may be divided. Often we have to simply test several different values for K and analyze the results to see which number of clusters seems to make the most sense for a given problem. The K-means algorithm clusters the data at hand by trying to separate samples into K groups of equal variance minimizing a criterion known as the inertia or within-cluster sum-of-squares.
Choose the number of clusters as the smallest value of k such that the gap statistic is within one standard deviation of the gap at k1. Beginequation dfracoperatornameBSSoperatornameTSS times 100 endequation. For every value of K calculates the WCSS value.
The suggested approach takes into account the inertia value for each possible K and weights it by a penalty parameter. Renesh Bedre 7 minute read k-means clustering. The basic k-means clustering algorithm is defined as follows.
It executes the K-means clustering on a given dataset for different K values ranges from 1-10. This algorithm requires the number of clusters to be specified. Lets visualize our data into two dimensions.
Now using putting the value 5 for the optimal number of clusters and fitting the model for doing. The quality of a k-means partition is found by calculating the percentage of the TSS explained by the partition using the following formula. The silhouette algorithm is one of the many algorithms to determine the optimal number of clusters for an unsupervised learning technique.
Based on what I have learned from these approaches I have developed an automatic process for choosing K- the number of clusters.

Using Weighted K Means Clustering To Determine Distribution Centres Locations Cilegon Distribution Sum Of Squares
Elbow Method For Optimal Value Of K In Kmeans Geeksforgeeks
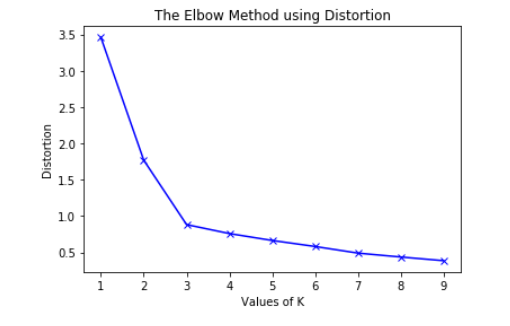
Elbow Method For Optimal Value Of K In Kmeans Geeksforgeeks



Comments
Post a Comment